Energy Efficient Planning
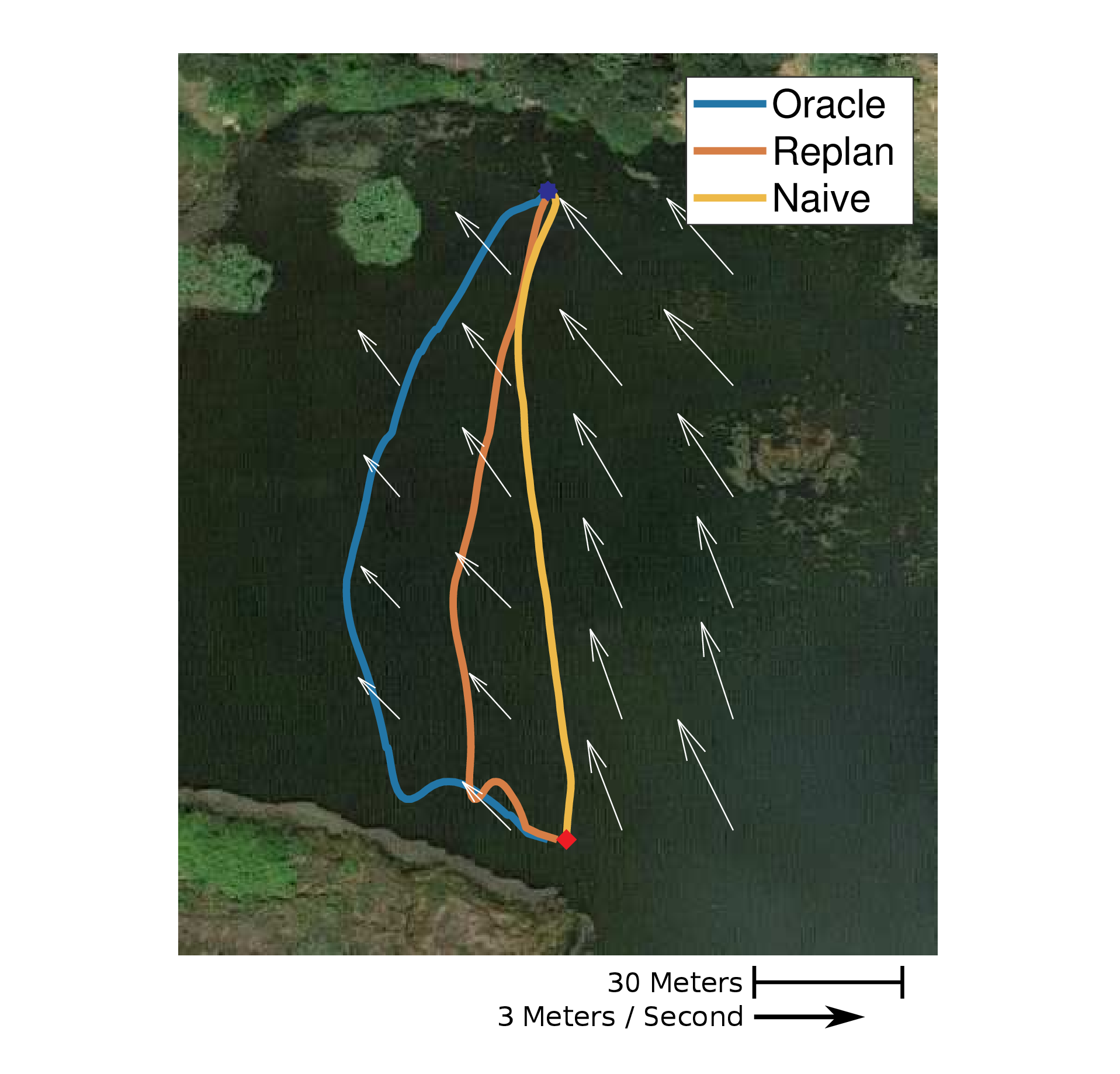
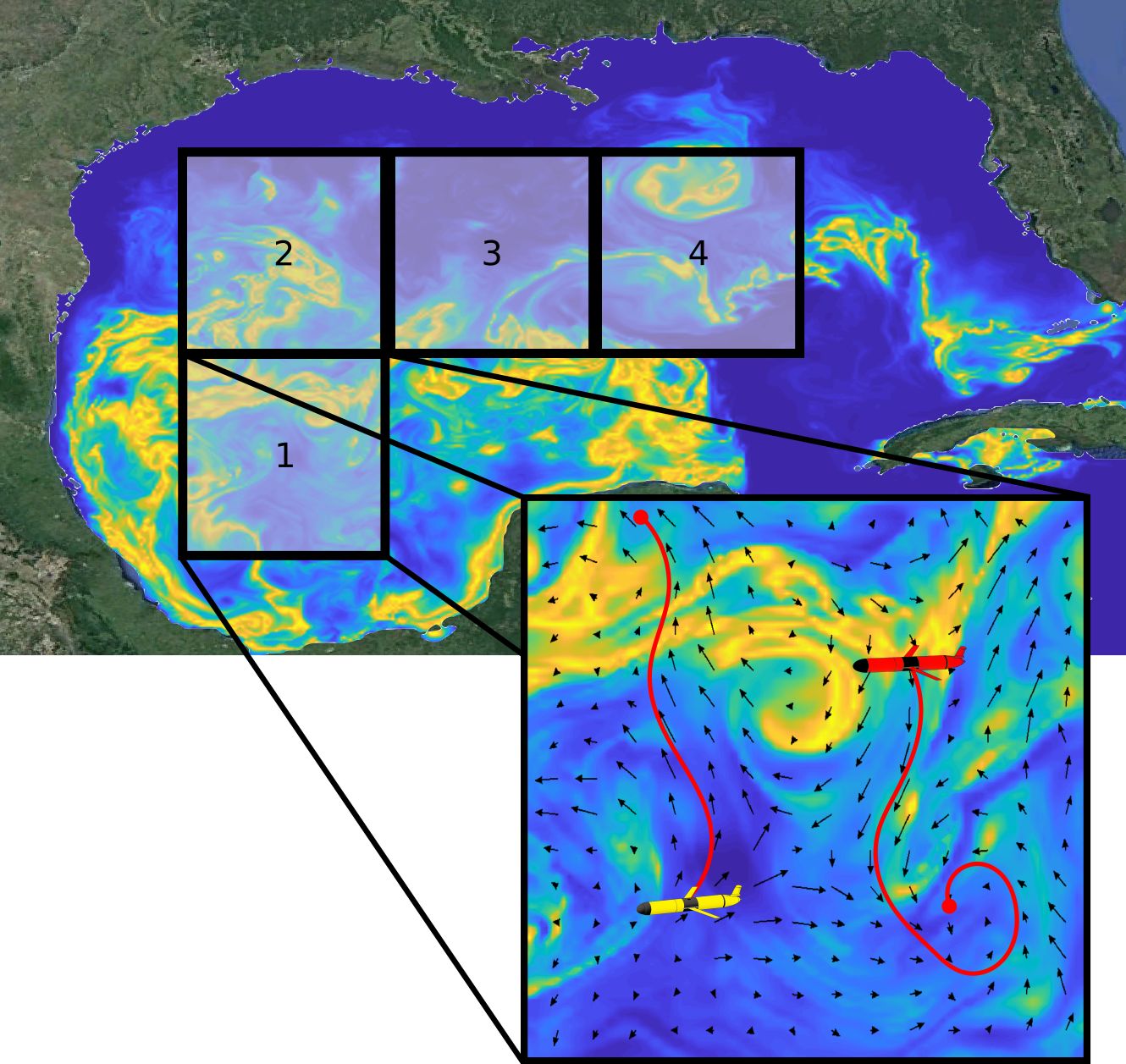
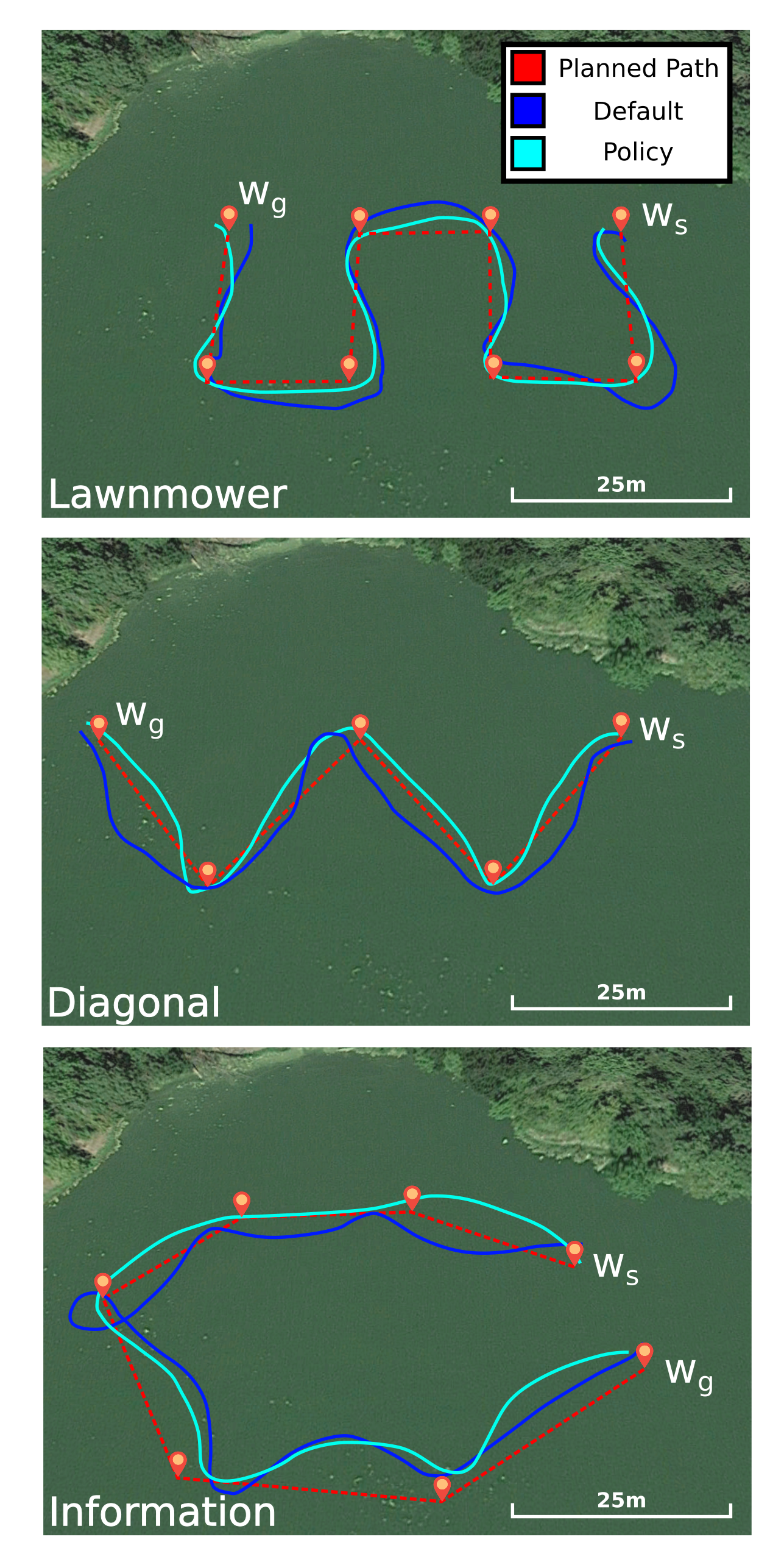
We were asking the question of how to plan energy efficient paths through strong and uncertain disturbances, such as ocean currents and wind fields. I developed the EESTO algorithm and demonstrated the benefits of this algorithm in both simulation and the field using a Platypus Lutra autonomous boat. In the image below you can see the paths the Lutra took on the surface of a lake in the presence of a wind field. In the field trials I tested three different planning methods. Note that the vehicle started in the upper middle (blue star) and moved to the lower middle (red square). First, we used a baseline method called Naive which ignored the wind during planning. Next we used a Replan method which started with no knowledge of the wind field but would replan as it gathered information about the wind. Lastly, we used an Oracle method which started with a map of the wind on the lake from a previous survey that day and would then replan with respect to the new information about the wind gathered during execution.